

LORAによってはトリガーワードを指定する必要があります
プロンプトに打ち込めばいいといえばいいですが、毎回打ち込むのもめんどくさいので、一定のトリガーワードを事前に設定しておいて、プロンプトと結合することを考えます
この時、結合の方法としては
- textの入力個所を複数作成し、最終的に一つにtextとして結合し、エンコード
- textを入力個所を複数作成し、各々エンコードした後にconditoningとして結合する
2パターンが考えられますが、それぞれどのように変化するのでしょうか?
検証
モデルは「animagine XLV3」でプロンプトは1girlのみの条件です

この画像に白黒化のLORAを通しますが、トリガーワードに「lineart,monochrome」を必要とします
【Anime Lineart / Manga-like】https://civitai.com/models/16014
Textを結合させてから変換する
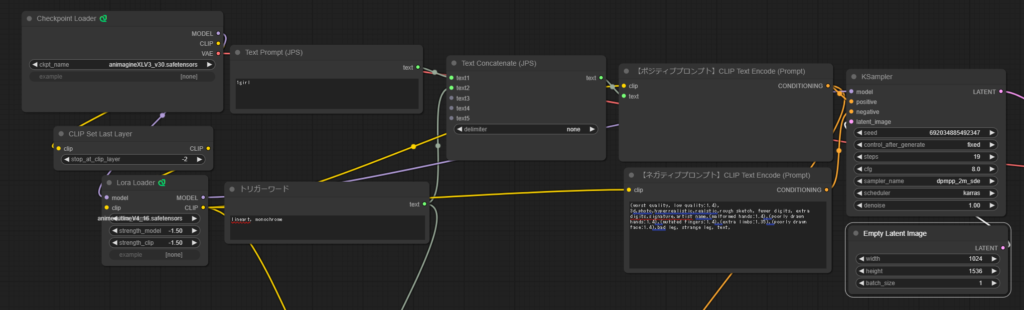
Text promptに「1girl」、トリガーワードに「lineart,monochrome」を指定して、Text Concatenateで結合し、変換、KSamplerに流し込んだ場合のイラストが、こちら。

きちんと白黒になっていますね。
シード値固定したんですが、結構絵柄が変わってしまいました・・・。
Textをエンコードした後に結合させて出力する
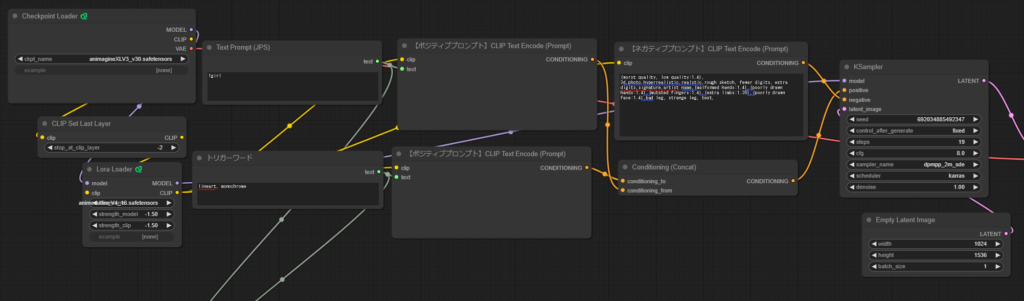
Text promptに「1girl」、トリガーワードに「lineart,monochrome」を指定してそれぞれをCLIP Text Encodeに通してから、Conditioning(Concat)を使用して統合した後にKSamplerに入力しました

こちらもきちんと白黒になっていますね。
シード値固定したんですが、やっぱり結構絵柄が変わりましたね。
4枚ずつ生成しての比較
Textを結合させてから変換




Textをエンコードした後に結合




いかがでしょうか?
いずれの方法でも望み通りの白黒化された画像は出力されましたが、絵柄には違いができていますね。
個人的な感覚ですが、Textを結合してから変換した場合はLORA側に絵柄が引っ張られてる感じが強いと思いますが、エンコード後に結合した場合は、白黒よりもグレースケールが強調されている感じがしますね
どちらのほうが良い・悪いはありませんが、目的によって使い分けてみるのがいいかもしれません!
この記事が参考になれば幸いです!!
コメント